After 4 years of prompting, I decide to embark on a practical exploration session and finally do something in the AI/ML space. In this post I write about it.
In this post, I learn a part of the very (practical) basics of all that, that machine learning is. I do this through an MVP for an idea I had for a while: a workforce analyst agent (basically a surveillance agent). Here is how it went:
Theory on AI/ML basics (Conceptual)
Practice I: Environments & Evals
PI Environments
Evals & Rubrics
Running evals on a text-based pseudo-game
Practice II: Synthetic data & preparing to fine-tune
Philosophizing about agents & creating a background metrics collector
Creating a synthetic dataset (20k-rows) based on the service
More evals
Practice III: Fine Tuning a LoRA with RL
First run
F1 & Gold IDs
Better than the first run
Practice IV: Infrastructure (vLLM, k8s, Modal)
Deploying Qwen3‑4B-Instruct-2507 & my LoRA-patched model on Modal
Solving cold start & boot times
Deploying my web application
Practice V: The results
Evaluating my LoRA against the base (+results)
Evaluating again with a newly generated dataset (+results)
Evaluating again with false positives & fake data (+results)
Closing Notes
Disclaimer: The surveillance agent uses synthetic data and serves as my own ai/ml learning exercise i.e. it is not real surveillance
I also made a video!
Theory on AI/ML basics
Models & Weights
In physical reality, everything is an atom. Atoms get structured into systems, and they interact with other such systems through the means our physical reality allows.
In software engineering, everything is a bit. Bits are combined into datapoints and datapoints get structured into data structures, and they interact with other data structures through the means our compute devices allow.
Having these two perception models helped me set my mind for the basics of AI/ML. Starting my chat, I ask it to give me the base and it starts explaining in a very non-beginner friendly manner what a model is, what weights are, and where sampling happens. Matrices, vectors, etc. etc… all, concepts that I had a hard time understanding. As so, I step back and start working with analogies.
The analogies I reach are as follow:
Model — A world and its physical limitations i.e. the earth
Weights — How we comprehend the systems by which we go by e.g. political systems we identify by, that shape how we think & act i.e. our morals and belief systems i.e. our long-term behavioural tendencies and learned patterns
Tokenizer — The “biological contract” in our brains that allows us to decode language and comprehend it.. english, chinese, whatever. It can shift.
Sampling — The level of intensity we react in certain situations. It varies.
Input — What happens to us like a car beeping at us, our girlfriend kissing us, or a teammate pinging us on Slack. It is external.
Context — Our situational understanding of the situation: the Slack sound; the car sound, location, color, etc; the weapon we are being attacked with; etc. etc.
Output — Our response to the situation (input + context) based on (x) our behavioral tendencies (weights)
Putting the analogy into a story, I end up with the following:
say i am a very conservative human male that speaks english (when my brain hears english speech, it enables my “tokenizer”) and i’ve had a rough day at work (working context). my kid wants to go out after 9pm. “just yesterday i deliberately told it it will not go out after 9pm this week”, i think (working context), so naturally here is what happens: the model (earth and its physical limitations) exist; in that model, i exist. me being me, i have an understanding of the world by my own morals (weights), and my kid comes to me and says “i want to go out!” (input) which then triggers a process in me (i am being inferenced): i look at it, i see its face, i get a contextual understanding of the situation and its request, remember what we spoke about yesteday (current context/state) which then triggers a “subconscious reaction” in my “brain” (weights) [that basically merges my current context + my subconscious understanding of the world i.e. weights] and i decide to shout out loud (because of my sampling settings) [instead of calmly denying.. which i would’ve denied the request in either way (weights)], “HOW MANY TIMES DO I HAVE TO SAY YOU CANNOT GO OUT AFTETR 9PM” (output)
With all of these concepts now engraved in my brain, I start getting technical. I apply my conceptual knowledge and I reach the following understanding:
Model — A combination of the architecture & weights.
Weights — The baked-in values that affect the response (like a constructor in a class, that upon initialization, gets “baked” into the instance)
Tokenizer — The contract by which a model processes the input it receives.
Sampling — The randomness of a
Input — Well… input
Context — Well… context
Output — Well… output
Model Architecture — The code architecture
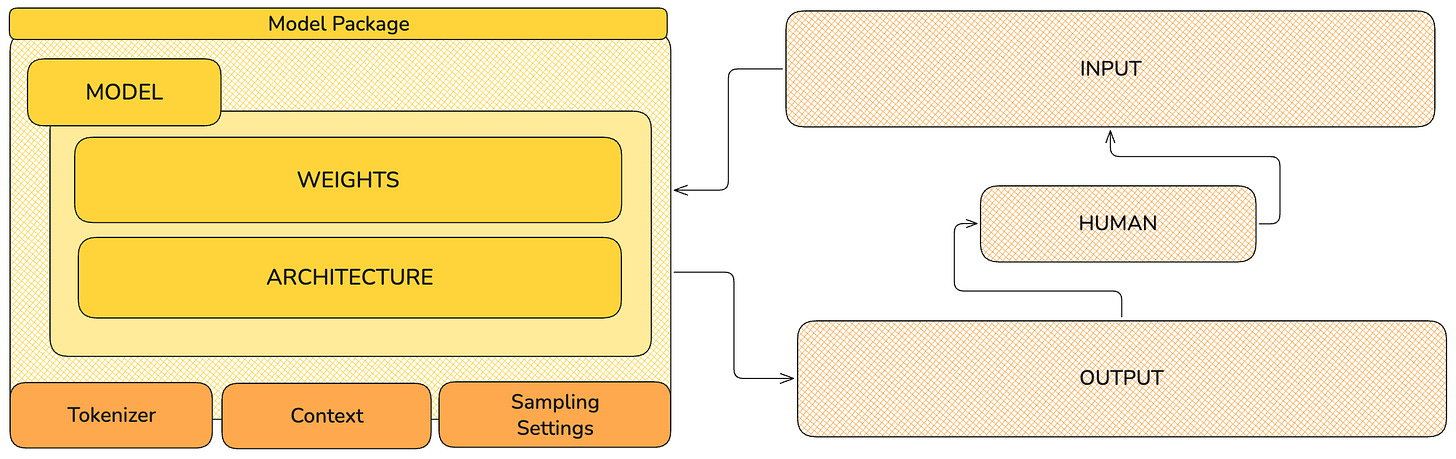
(here is a diagram I created with my newly acquired knowledge)
So if I put it in programming terms—I do this second analogy so I can start shifting my brain to think about it technically, based on my experience in the industry—the architecture is a Class, and the weights are external data loaded by the constructor of that class. Then inside this class, I have methods that reference the weights. When I initialize the class, I initialize it with certain weights, so then when I invoke a Class method, it works with those weights.
A logical representation of: architecture (code) + weights (data), which together define a runnable function (inference).
After I conceptually understood what a model is (and partly how it works), I moved on to “reinforcement learning”, “LoRA”, and “evals”. It was a lot more easier for me to understand these concepts so I didn’t need to translate them into abstract analogies:
Reinforcement Learning: a training technique where a model has a concrete goal and with its attempts to reach it, it is being awarded when it succeeds.
Evals: a set of techniques used to evaluate a model’s performance while it is being RL’d
LoRA: a small set of additional weights learned during fine-tuning that can then be added on top of the model’s base weights
With this, I now feel I have a good enough understanding of what I am about to do, so I continue in practice.
RL with Prime Intellect + Modal
Practice I: Evals & Rubrics
The first thing I do after reading through PI’s docs for their hosted RL feature was to install the prime cli and initialize my first local PI lab. I then initialize the starter evals environment. I explore the repository and notice there is no rubric configured. I didn’t know what a rubric is at the time, so after a short conversational back-and-forth with Codex, I acquire the following understanding:
A rubric is a set of rules used to evaluate a model’s performance and reward correct responses. Pretty straight-forward.
This is what a rubric looks like:
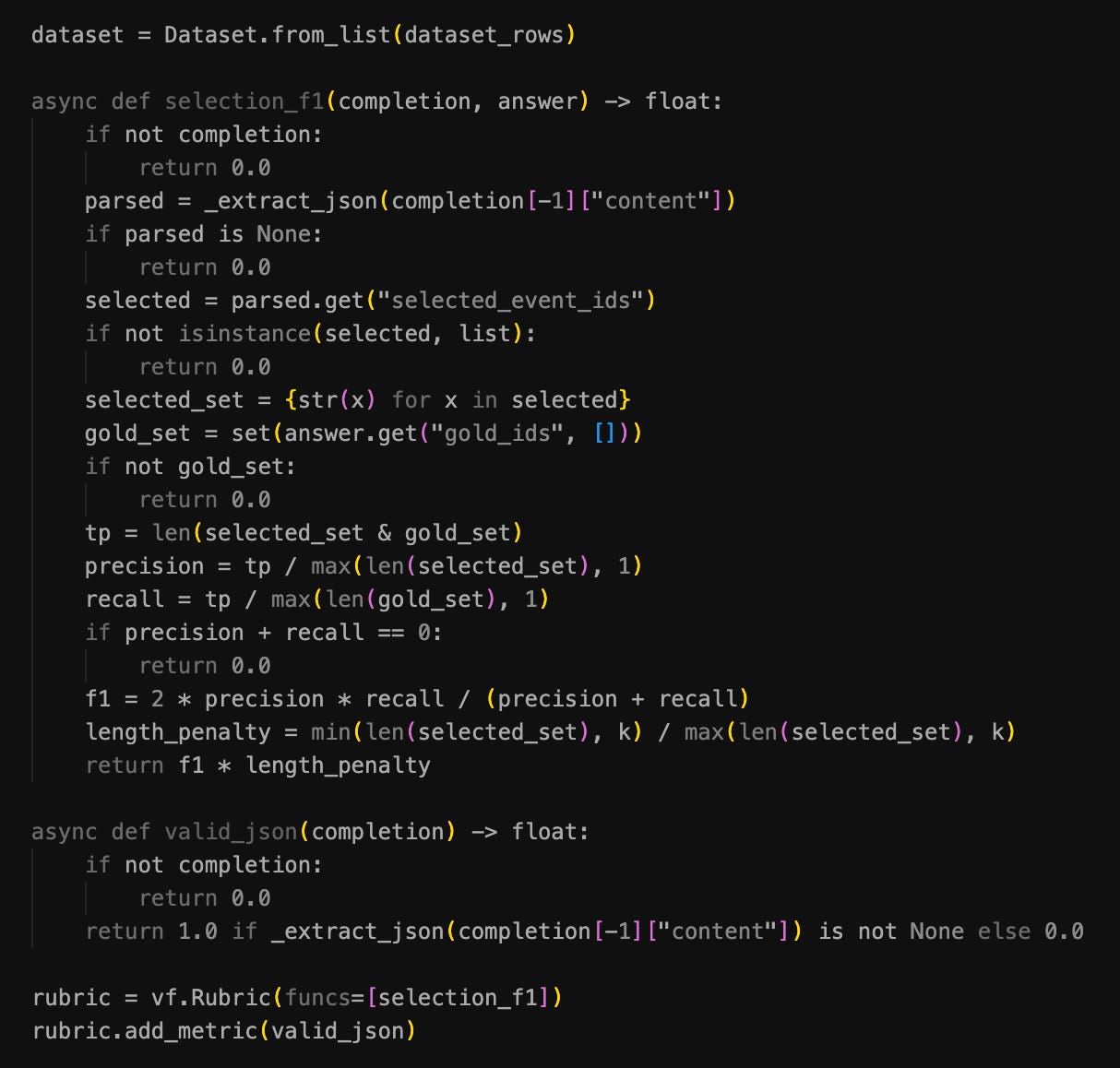
In this particular screenshot, the response is being compared to expected output and the precision/recall mean (f1) is used to generate the score. I write about this later.
With this, I proceeded to run my first eval. I do not have any ideas as to what to evaluate, so I decide to create a basic text-based puzzle game where the model has to choose one of the four actions: left, right, up, down.
Done with my game, topped up $10 in funds, and tested locally, I run my first eval.
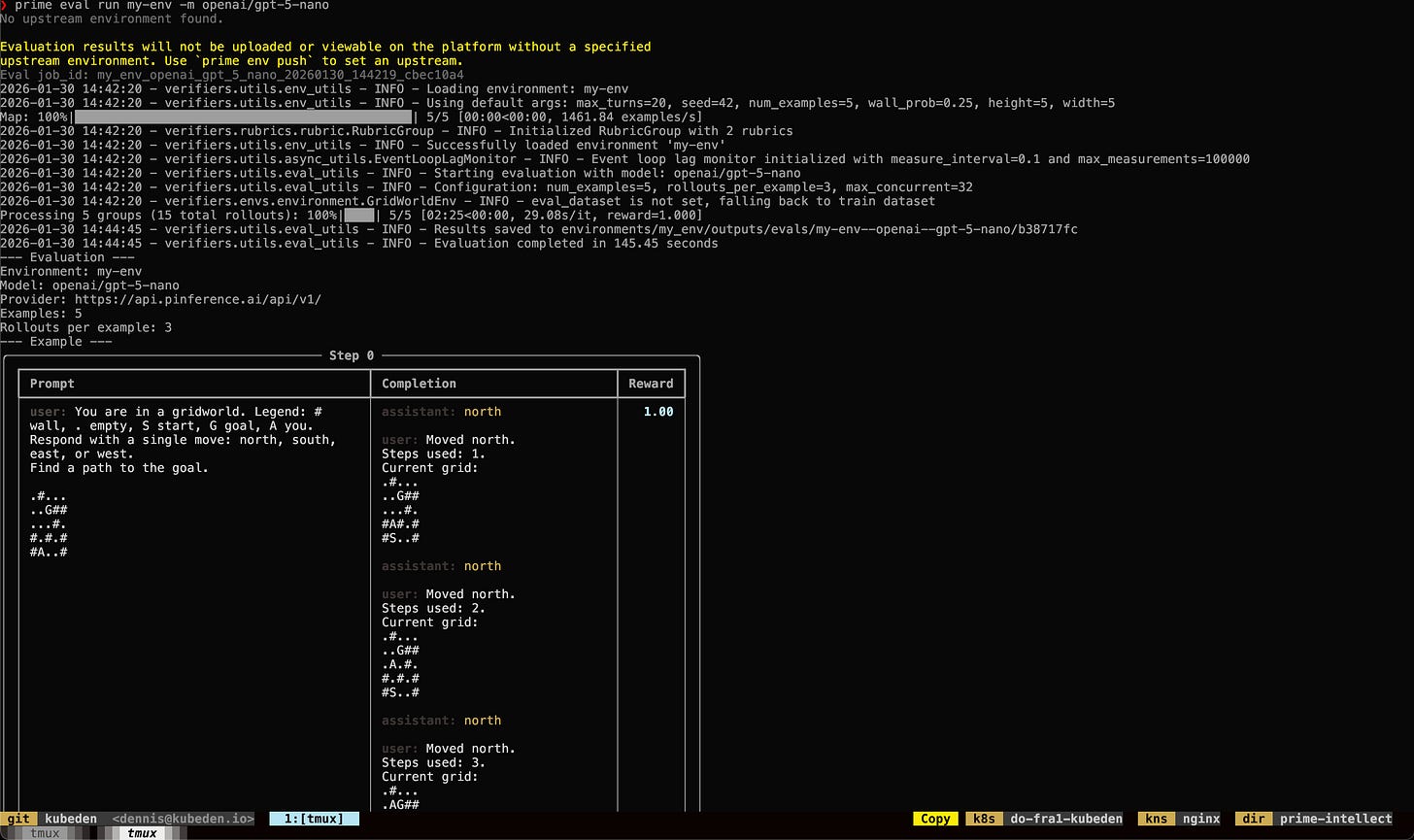
After that, I decide to give prime eval tui a try:
While the text-based representation of my pseudo-game’s mazes was not good, I understand what the core concept of evals. It is to have an “environment”, which in my case is a terminal-based game, in which there needs to be clear actions & goals, and also a clear way to evaluate if an action is positively impacting the end destination i.e. on a right track to reach a goal.
Feeling good with myself for the reason I ran through an entire eval process and I understood it, I feel ready for the next step: “pre-training a model with RL” (at the time I did not understand that but I was actually fine-tuning a LoRA adapter… not pre-training a model).
To pre-train a model means to train a model from the ground up. The very first step. After that, one fine-tunes a model.
Practice II: Synthetic data & RL fine-tuning
Having a newly-formed, basic intuition of what’s going on, I decide I want to apply my knowledge into a project with a clear end-goal so I can evaluate & retrospect on my own work (heh, ironic). I decide on an idea I’ve had for a while: a “workforce analyst” agent that would collect data of how I use my computer, process the data, and be trained in a way to “judge” if I (or anyone, really) was productive or not.
During this stage, I had a mild technical ideation crisis, because I could not agree with myself on what exactly defines an agent. I could not understand why I am doing this, since the big models are good enough. I also could not understand why there is the need for me to apply AI/ML to create a personal agent, but then I reached a revelation, through the knowledge I acquired in my theory stage: an agent is a combination of a model (brains) + harness (tools), which allows (equals=) certain capability (integration), that is able to interact with an environment. An agent is just a deterministic system that interacts in a non-deterministic way. In a way, it is a non-deterministic automation technique.
So in a way, I need AI/ML in cases where I need to achieve as much quality & performance on a very specific process I’d like to deterministically automate through allowed non-determinism. In a way, I am doing all of this so I can increase the odds of success of whatever I expect an end result of a non-deterministic action to be.
With my understanding now clear, I divide my end goal in two parts:
Non-ML part (deterministic)
ML part (non-deterministic)
I start with the non-ml part. Particularly, with the data collection. For that I decide on a json structure (the “shape” of what I am going to collect), as well as the way I’ll collect it — through a background service. I generate some code and after 15 minutes of iteration I have what I want. Here is a screenshot of the data collection log:
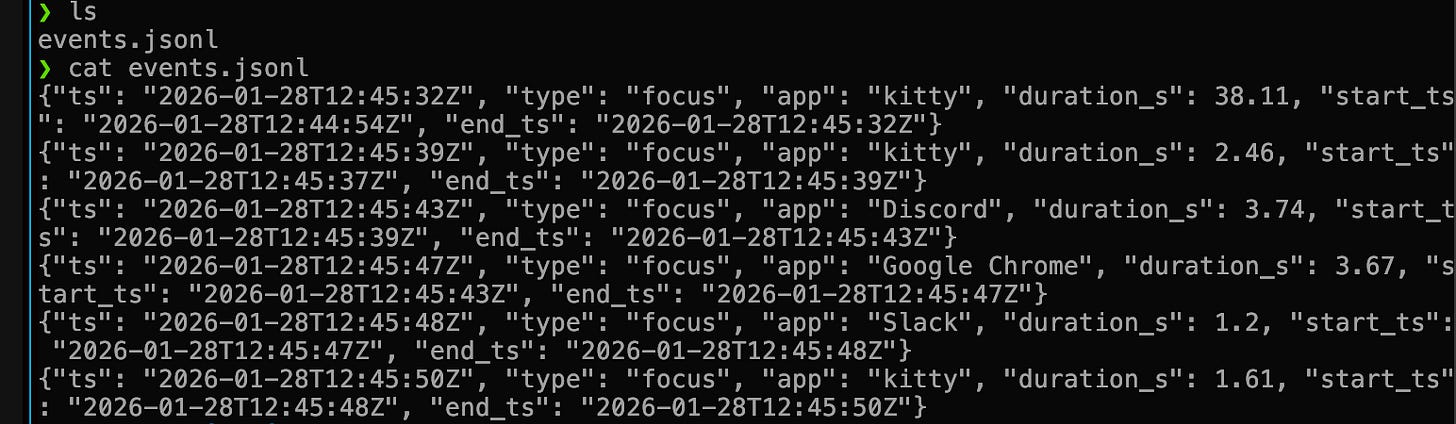
I am now able to better visualize what I chase and as so, I continue into the second part of my implementation (ML) by writing a rubric and running an eval so I can see what is possible. I create a new pi environment and a rubric matching my json, and then I execute an eval.
I had to touch up the rubric / prompt a couple of times because it either rewarded hallucinated responses, or the json the model would respond with would not match my desired structure.
After a couple iterations, I feel ready to pre-train my first LoRA adapter, so I push my environment to the (PI) environments hub and I load my gun.
Practice III: RL & Iteration
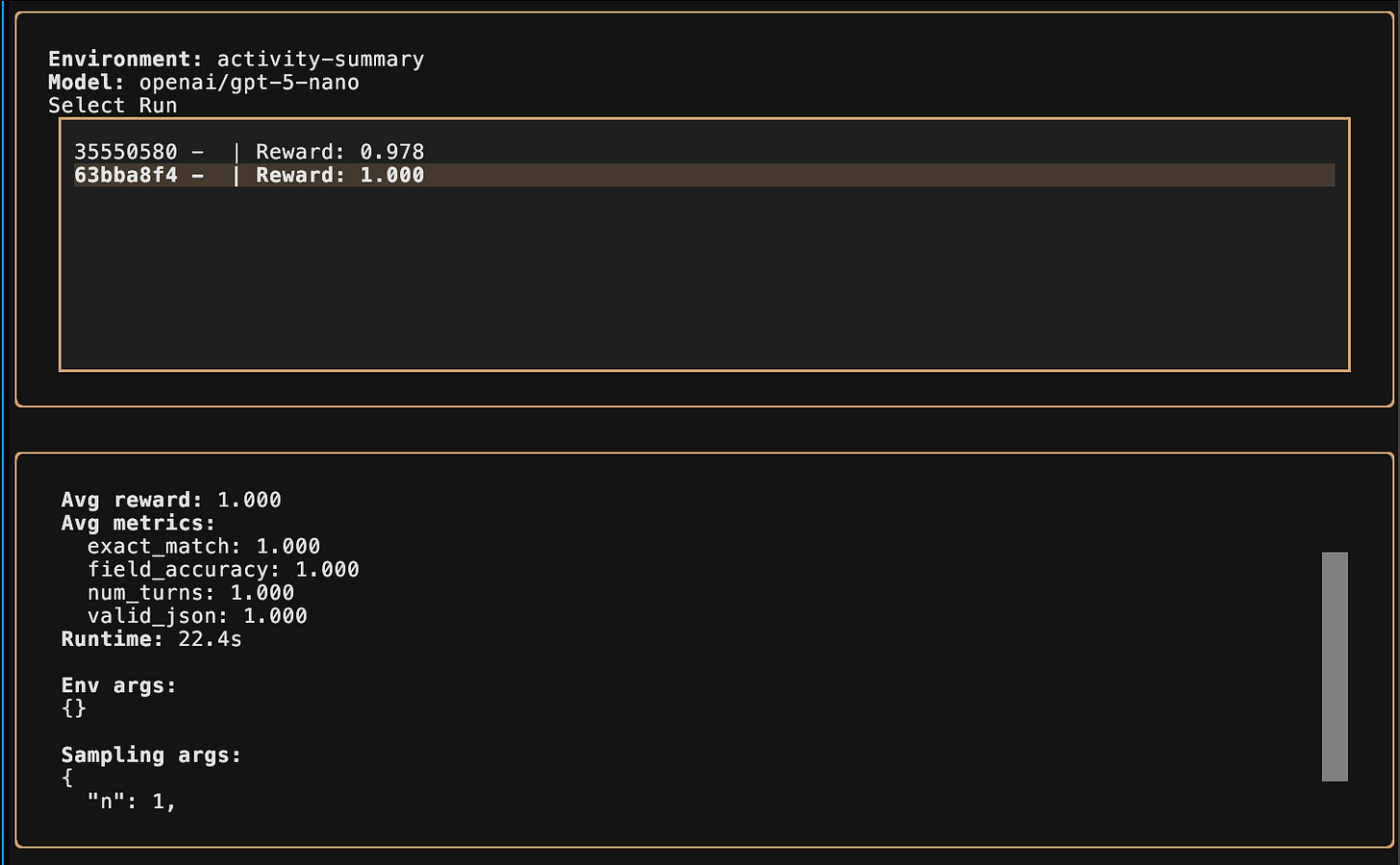
I observe that my model is successfully being fine-tuned and I step away for some time. After coming back, I see that it had successfully completed the run and the graph looked somewhat satisfying (or at least so I thought):
Unfortunately, after showing the graph to Codex, it suggests we do more varied evals on the task (successful classification & understanding of “computer use” metrics), because (in it’s words):
The task I’d set was way too easy for the base model
There was no F1 metric (I did not know what an F1 is)
The base model’s performance was constantly as follows:
- valid_json = 1.0, field_accuracy ~0.98, exact_match high
Which confused me big time, because the graph showed a variety in reward… meaning, it sometimes succeeded, sometimes didn’t..? Meaning.. the task was not “too easy” for the base model!
Understanding this, I ask Codex what is happening and it introduces me to the concept of F1 — a number (score) that is computed from the values (scores) of the precision & recall capabilities of a model. It is high when both are high. This is usually used in evals, but in my case, I use it as a reward signal because what I am training on (the exact json structure of my surveillance agent metrics) is specific enough to allow me to ask questions like: “how many metrics of the 8 i selected are correct” (precision) + “of all the correct events, how many did I select” (recall).
Codex also introduces me to the concept of “gold IDs” or “gold labels”, which is basically a ground truth used to compute the F1 against the model’s output.
Here is an example from my task:

These are two real values from my dataset. Even though the second one looks as it confirms low productivity, it is a decoy because in reality, having a short session of focus and switching context does not always mean you have been unproductive, contrary to being idle for 581 seconds (the first event) which is a clear tell.
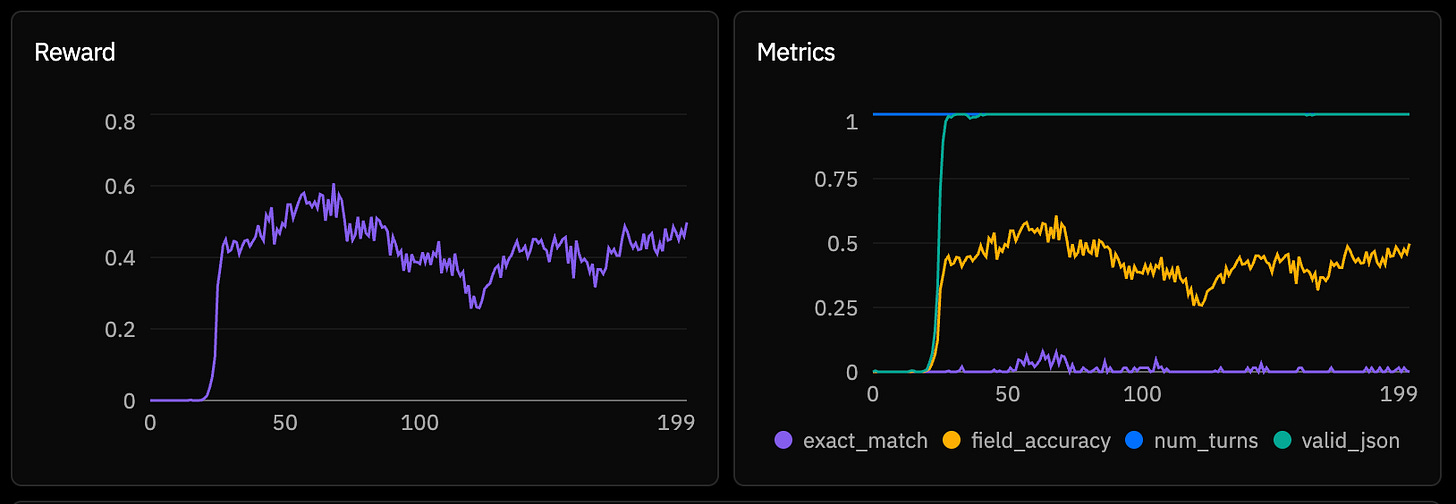
With this new F1-oriented environment, I execute a new run on a smaller subset (2k samples), and for the first time the reward graph show a clear sign of successful learning: consistent and small in variety:
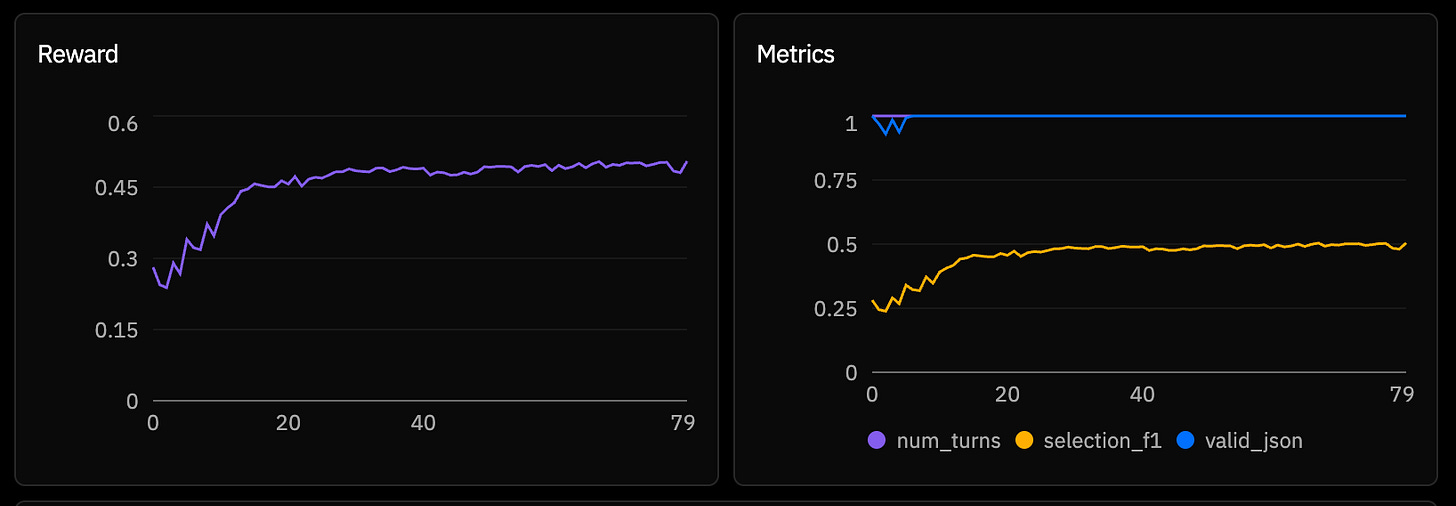
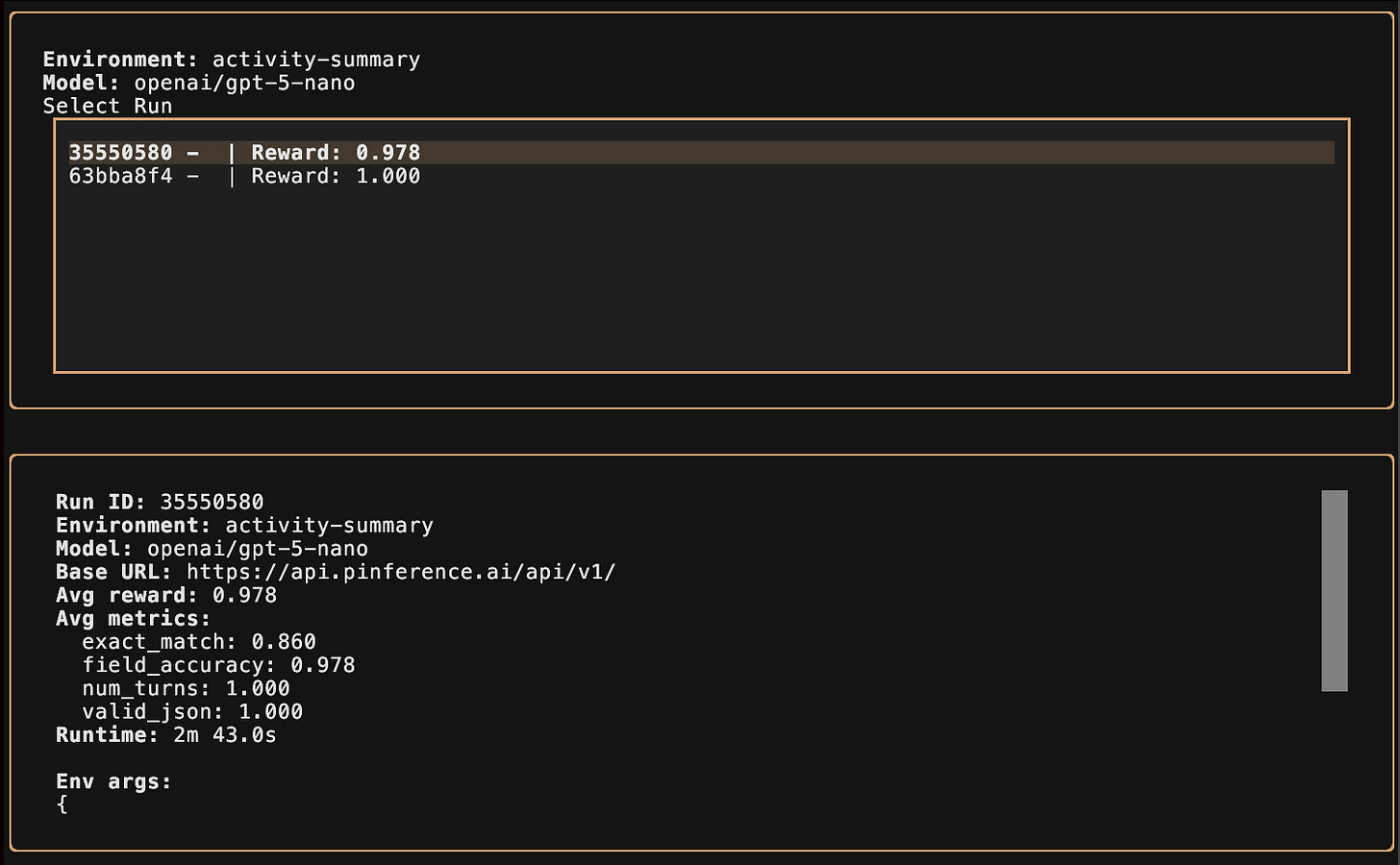
While my run is small (80 steps), it is more than enough for me to have proven to myself that I have fine-tuned a model. What is left now, is to evaluate it against the base model. Which means… that I have to host it :S
Practice IV: Self-hosting an 4B-parameters model (vLLM, k8s, Modal)
Having my run completed, and my excitement high, I can’t wait to try and compare the base model against my LoRA-patched one. There was only one small problem: I didn’t know how to attach my LoRA adapter onto the base model. It turns out that Prime Intellect does not yet provide such a service… I am only able to download my LoRA adapter. So from there, I was on my own.
Initially, I had high hopes of self-hosting my base model (Qwen/Qwen3‑4B‑Instruct‑2507) on my k8s cluster, so I attempt to add a GPU node to my DigitalOcean k8s cluster, but it turns out that they do not allow the inclusion of GPU nodes in my region. In retrospect, that was beneficial for me, because I would’ve probably forgot about my node and pay $600 at the end of the month. Close call…
At this point, I start exploring my options and I come across the following two PaaS providers:
While RunPod seemed like a cool learning experience, Modal’s free tier and ease-of-use made it a no-brainer for me, so I go for Modal.
I download my LoRA adapter from PI’s portal, write a modal.App script, and create an account. Then I deploy my first container. It all felt kind of like having a Dockerfile, except it was all programmatic and not declarative.
I serve my model but upon attempted inference, I am bashed with the following error:
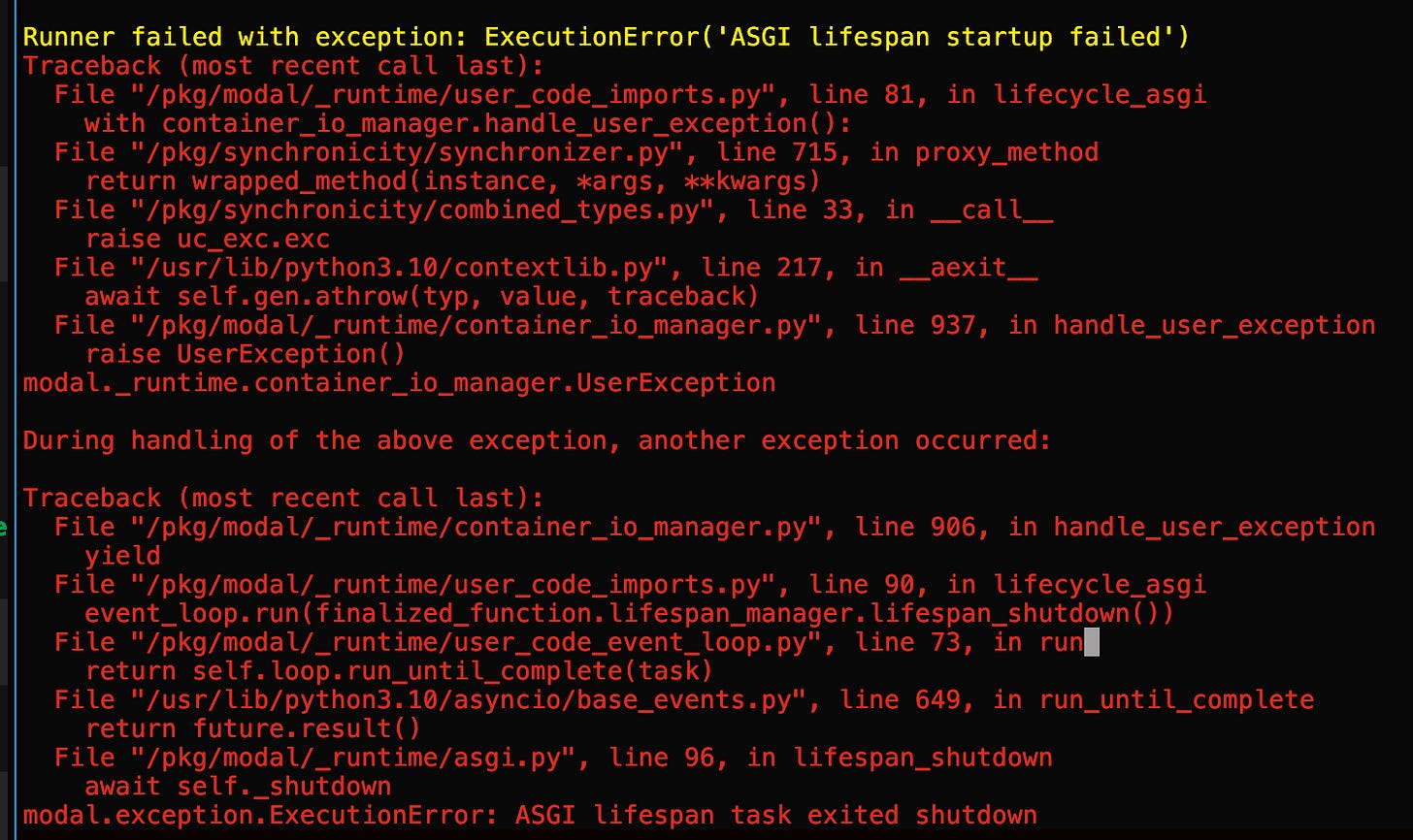
I enable more concrete logging and figure out I am missing some configurations. Fixed. Then another problem: the boot time of my container takes 3 minutes every time I attempt to inference it… This happened because every time send a new request, it would just cold-start a new, separate container. I don’t want my app to be set to always-on, so I solve this by creating a “ping” script. The script sends a GET /v1/models request to my endpoint to get the active models, and that would keep my container alive.
With this configured, I now have infrastructure to use and compare the base model vs my LoRA-patched one.
To recap the infrastructure part, I deployed a vLLM server on Modal with my base model and my LoRA adapter included. With vLLM, one can call the base model with or without the LoRA. One can also have many LoRA adapters to inference on the same vLLM server. vLLM is like Apache2/Nginx, but for LLMs.
Practice V: Base model vs LoRA-patched model
I create a basic evaluation script that would call both the base and the LoRA-patched endpoints with the same prompt and with the same records from the dataset. This shows the following result:

Seeing the good improvement, I become happy, but I do not let my tiredness & desire to finish this journey break me. I have to put in the work and make sure what I did is good. In this particular test script, the test happens on a very small number of samples and the dataset values are actually the ones from the training data… which leads me to believe the good improvement (result) comes from the fact my model already has the values in its LoRA. So I iterate.
In my second testing, I introduce more records per run, multiple runs, and debug samples. The point of debug samples is to make sure that the result is not hallucinated / wrong:
❯ python learnings/modal-vllm/compare_models.py
--- DEBUG SAMPLE ---
Gold: ['e002', 'e057', 'e055', 'e058', 'e037', 'e005', 'e046', 'e015']
Base IDs: ['e002', 'e003', 'e012', 'e014', 'e016', 'e020', 'e022', 'e035']
LoRA IDs: ['e002', 'e027', 'e049', 'e054', 'e055', 'e057', 'e058', 'e059']
Base overlap: ['e002']
LoRA overlap: ['e002', 'e055', 'e057', 'e058']
--- DEBUG SAMPLE ---
Gold: ['e002', 'e057', 'e055', 'e058', 'e037', 'e005', 'e046', 'e015']
Base IDs: ['e002', 'e003', 'e012', 'e014', 'e016', 'e020', 'e022', 'e035']
LoRA IDs: ['e002', 'e027', 'e049', 'e054', 'e055', 'e057', 'e058', 'e059']
Base overlap: ['e002']
LoRA overlap: ['e002', 'e055', 'e057', 'e058']
Base model times (s): [3.32, 3.07, 3.03, 3.36, 3.07, 3.21, 3.36, 2.99, 3.08, 3.37, 3.05, 3.03, 3.4, 3.03, 3.06]
LoRA model times (s): [3.64, 3.27, 3.24, 3.59, 3.2, 3.25, 3.69, 3.19, 3.33, 3.69, 3.29, 3.2, 3.62, 3.29, 3.22]
Base model avg (s): 3.16
LoRA model avg (s): 3.38
Base precision/recall/F1: 0.2 0.2 0.2
LoRA precision/recall/F1: 0.5 0.5 0.5
Base output:
{
"selected_event_ids": [
"e002",
"e006",
"e009",
"e011",
"e015",
"e018",
"e022",
"e037"
LoRA output:
{
"selected_event_ids": [
"e004",
"e013",
"e014",
"e041",
"e019",
"e046",
"e040",
"e012"
After these results, I am happy with the representation of the information and the clear proof my model is doing better than the base one.
As I am just about to wrap it all up, I do one last iteration: I create one more script, that would again re-generate all the metrics but this time also introduce false positives and fake data. I run the model again. Same concrete proof of success:

And with this, I put an end to my learning and I get ready to engrave it all down in this very blog post. Phew… what an experience.
Closing
I started this exercise at lunch on Wednesday, Jan 28th with the intention to finish it by the evening. It is now Sunday, Feb 2nd. I feel very tired mentally, but at the same time—very satisfied with the amount of new knowledge I now have.
I learned a great amount of concepts, thought about them for hours during the span of 5 days and put them into work. Then, after numerous iterations and concentrated effort, I got an end result that was clearly evaluable. The evaluations showed success.
It is a good feeling, you know… doing all this. “Why did I do it”, I ask myself. Is it to get an appraisal? To get noticed? To prove something to me…? To someone else? No. Even though those were my authentic initial assumptions as to why I’m doing all this, I now understand none of these had a place in my motivation reserve. I now understand that I did all that because I needed to click a very specific button in my brain. This button is called “purpose”.
You see, with the emergence of LLMs I’ve been feeling like I had lost my purpose for well over a year now. Ever since terminal agents arrived. And I have written about this numerous times already, so I won’t expand on it here. What is important is that during these 5 days, I felt like I had purpose. And now I think more about this: “where does my purpose arise from?” — and it becomes clearer. I am a very chaotic person, and I often lose interest. I need dynamism. I am also a person who loves to prove to myself that I am capable of doing hard things. So in a way, this 5-days-long exercise was both an escape from my dayjob, as well as a main-campaign quest.
I love to think about stuff that my managers don’t want me to think about. I love to put myself in imaginary situations where I am my own manager. Where I do stuff for the sake of my own curiosity and I get to make a living out of it while also not having a ceiling to eventually reach and get boxed by. I often fall in an over-analysis loop where I reach a momentary conclusion: “You have to do one thing and one thing alone and only then you are going to be able to generate value for yourself and those around you!”. And that, combined with my wide interest spectrum, as well as my long-lived interest in single-branded actions, often demotivates me. But here I am, writing this post. For myself, not a manager. I feel strong excitement because what I did here made me feel good. What I do now (writing this blog post) makes me feel good. And I understand: I don’t need to do AI/ML only. Or DevOps. Or programming. Or anything one-dimensional. Tech is an entire world and I can do whatever the f*ck I want in it.
As far as AI/ML is concerned: I didn’t like it. It feels slow. While it manages to fit my perception of “satisfaction”, it does not do it when it comes to “fun”. It feels very min-maxy… and being the chaotic person that I am, I find it unbearable to have to wait [x] nr of hours so I can test my trained model. The concepts are cool and I guess the mathematical side of it is amazing, but this is simply not me. I think I’ll just continue harvesting the models and translate their capabilities into agents. In fact, I have logically grouped all of my interests towards agents under a single name: A2W, which stands for Autonomous Twins.
Anyhow. This is about it for this blog post. Thank you for reading this very long practical self-reflection into (once again) my search for purpose, and in regards to that, as it seems… I am getting closer and closer with each day. And this time… well, it felt like the very models that stripped me of my purpose assisted me in finding it again. Momentary. But it was there.
— Dennis
This Substack is reader-supported. To receive new posts and support my work, consider becoming a free or paid subscriber.